Member-only story
Dense layers explained in a simple way
A part of series about different types of layers in neural networks

After introducing neural networks and linear layers, and after stating the limitations of linear layers, we introduce here the dense (non-linear) layers.
In general, they have the same formulas as the linear layers wx+b, but the end result is passed through a non-linear function called Activation function.
y = f(w*x + b) //(Learn w, and b, with f linear or non-linear activation function)The “Deep” in deep-learning comes from the notion of increased complexity resulting by stacking several consecutive (hidden) non-linear layers. Here are some graphs of the most famous activation functions:
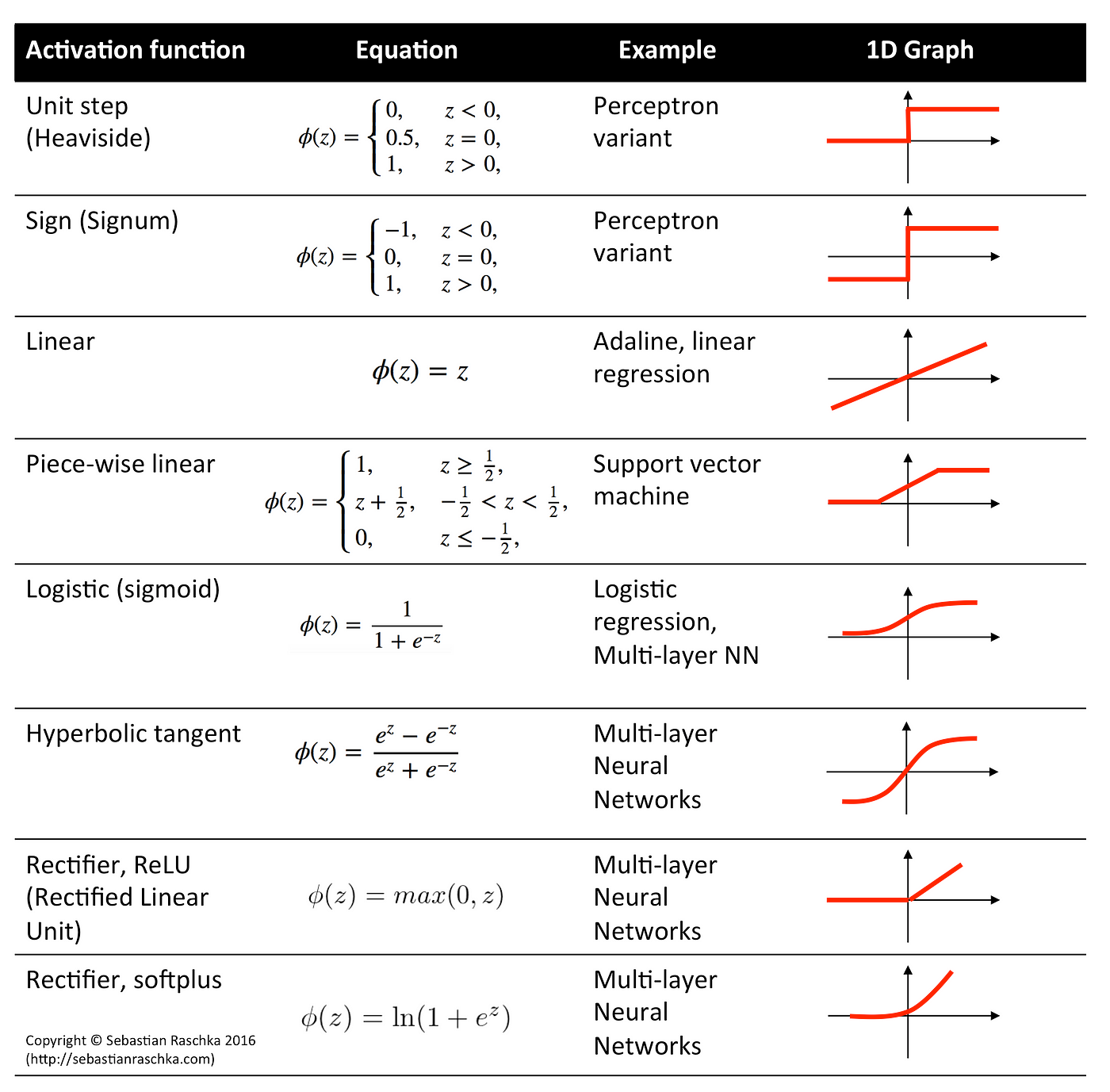
Obviously, we can see now that dense layers can be reduced back to linear layers if we use a linear activation! But then as we proved in the previous blog, stacking linear layers (or here dense layers but with linear activation) will be redundant.
Intuitively, each non linear activation function can be decomposed to Taylor series thus producing a polynomial of a degree higher than 1. By stacking several dense non-linear layers (one after the other) we can create higher and higher order of polynomials. For instance, let’s imagine we use the following non-linear activation function: (y=x²+x). By stacking 2 instances of it, we can generate a polynomial of degree 4, having (x⁴, x³, x², x) terms in it. Thus the more layers we add, the more complex mathematical functions we can model.
Limitations
Dense layers add an interesting non-linearity property, thus they can model any mathematical function. However, they are still limited in the sense that for the same input vector we get always the same output vector. They can’t detect repetition in time, or produce different answers on the same input.
If we are in a situation where we want that:
- If the first input = 2 the output will be 9
- But if the next input is 2 again the output should be 20 now.
We can’t model that in dense layers with one input value. Because if f(2)=9, we will always get f(2)=9. If we want to detect repetitions, or have different answers on repetition (like first f(2) = 9 but second f(2)=20), we can’t do that with dense layers easily (unless we increase dimensions which can get quite complicated and has its own limitations). That’s where we need recurrent layers.
If you enjoyed reading, follow us on: Facebook, Twitter, LinkedIn

